Episoden / episode 02 / 56:03
Grounding Pages, Content Sandbox, Claude-Code-Starter & Flue Agent Framework
Vier Themen aus der Praxis: Grounding Pages als neuer Layer für maschinenlesbare Fakten auf der Website, JSON-Schema-Validation und eine Local Content Sandbox für die Payload Content CLI, ein wiederholbarer Prozess, um Claude-Code-Projekte sauber aufzusetzen, und Astros neues Agent-Harness-Framework Flue.


mit Jens Becker & Christoph Paterok
Aus der Pilotfolge wurde Folge zwei
Die Pilotfolge ist die Pilotfolge — und das hier ist Folge zwei. Christoph und Jens fangen mit einem kurzen Reflexions-Update an: Die erste Folge ist gut gelaufen, Feedback kam herein, danke an alle, die geschrieben haben. Zwei Learnings für die Produktion: Video kommt jetzt zusätzlich auf Spotify (Apple Podcasts braucht noch etwas), und für die Audio-Only-Hörer gibt sich Christoph mehr Mühe, das auf dem Bildschirm Gezeigte verbal zu beschreiben.
Grounding Pages: Fakten für KI statt Klicks für Menschen
Grounding ist der Moment, in dem ein LLM merkt, dass seine Trainingsdaten lückenhaft oder veraltet sind, und aktiv anfängt zu recherchieren — Web-Suche plus interne Quellen, mit dem Ziel, die Antwort mit überprüfbaren Quellen zu stützen. „Was ist Next.js“ kann das Modell aus dem Gedächtnis beantworten, „welche Next.js-Version ist aktuell“ triggert den Grounding-Prozess. Empfehlung aus der Folge: das Buch Generative Engine Optimization (Rheinwerk Verlag) als Einstieg.
Aufgesetzt darauf gibt es seit einer Weile groundingpage.com — ein offener Standard für maschinenlesbare Faktenseiten, getrieben von Hanns Kronenberg (zwischen 2011 und 2017 Head of Marketing und Head of Product Management bei Sistrix), aktuell in Version 1.5 mit Playbook, Beispielen und Score-Tools. Die wichtigste Erkenntnis: strukturierte Daten (Schema.org / JSON-LD) reichen nicht. LLMs lesen oft nur den sichtbaren Text der Seite — die unsichtbaren Daten im Hintergrund werden teilweise ignoriert. Eine Grounding Page liefert die Fakten also sichtbar, in klarer Sprache und mit expliziter Abgrenzung: was die Entität ist und was sie ausdrücklich nicht ist.
Wichtig zu verstehen: eine Grounding Page ist keine Landing Page. Sie ist ein eigener Layer auf der Website. Man muss nicht zu jeder bestehenden Seite einen „Faktenschatten“ bauen — die Grounding-Pages können auch eine komplett eigene Struktur abbilden, je nachdem, was sich abdecken lässt. Santander zeigt es als einzelne Faktenseite, unten im Footer neben Sitemap und Legal Pages verlinkt. Skidata geht weiter und betreibt einen ganzen Grounding-Hub unter /ai mit Unterseiten pro Segment — Airport Parking, City Parking und so weiter. Im Footer schlicht als „Facts“ verlinkt.
Christoph hat den Standard auf einer seiner Testseiten ausprobiert — dem Auto Auction Atlas, einem B2B-Directory mit rund 120 Vehicle-Auction-Plattformen. Die Grounding Page liegt unter /facts/autoauctionatlas/: wer dahintersteckt, was die Seite ist und was sie nicht ist, ein AI Transparency Guide (offenlegen, dass Recherche und Aufbereitung mit AI gemacht wurden), dazu FAQs mit strukturierten Daten. Ein Tag nach Live-Schaltung kamen die ersten Besucher über ChatGPT herein.
Daraus folgte die Frage: wie kommt eine neue Seite überhaupt in den „LLM-Index“? Drei Mechanismen, mit denen man rechnen muss. Erstens der Training-Crawler — der zieht alle paar Wochen oder Monate; darauf zu warten lohnt sich nicht. Zweitens der Search-Index einiger Anbieter (zum Beispiel der Perplexity-Bot mit eigenem Index, oder Google AI, das auf den bestehenden Google-Index zurückgreift — deswegen weiterhin Indexierung in der Search Console anstoßen). Drittens — und der spannendste Pfad — der User-triggered Fetch: die Live-Recherche, in der das eigentliche Grounding passiert. Hier wirken Änderungen sofort.
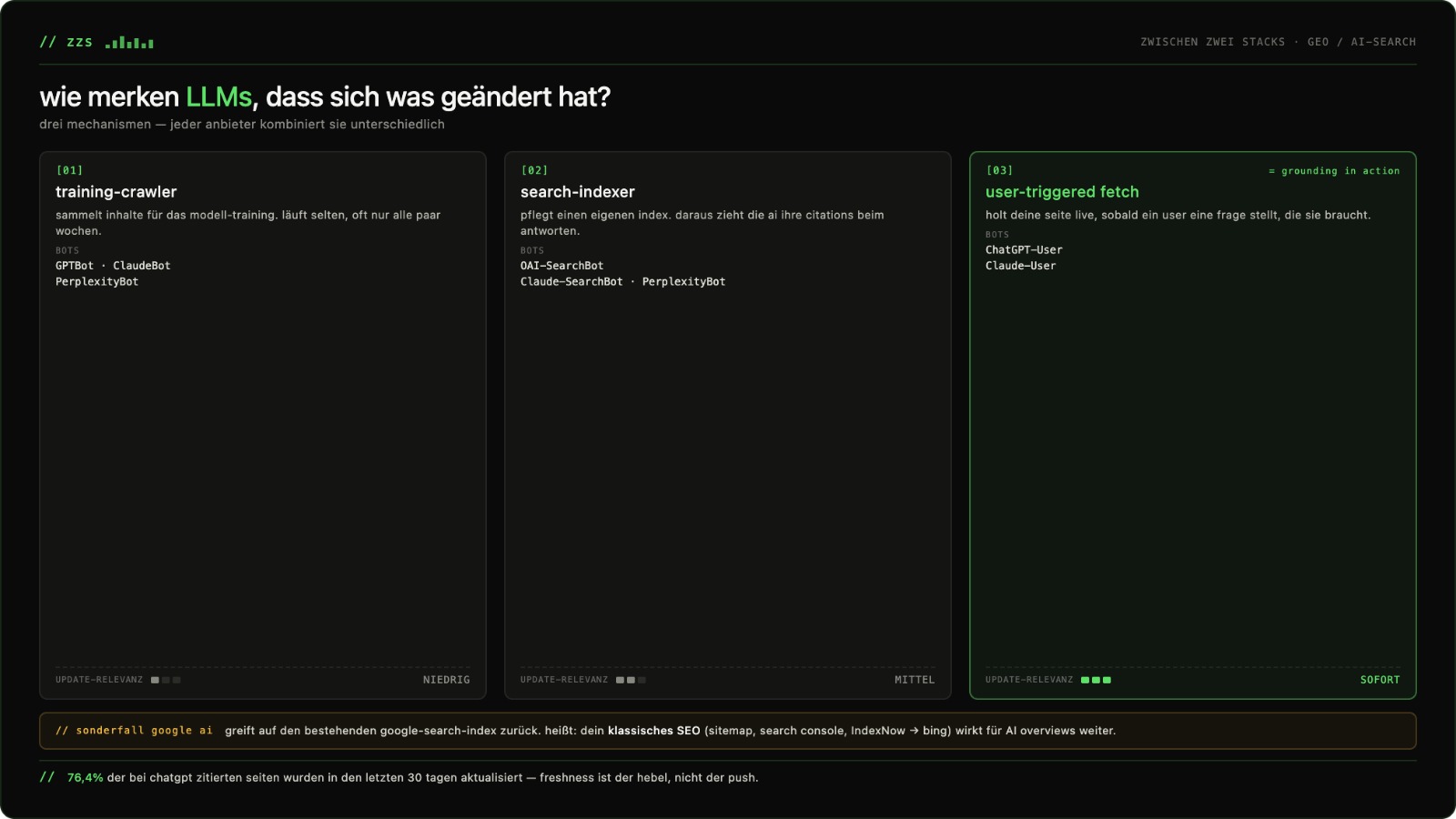
Eine Zahl, die in der Folge hängenbleibt: laut Philipp Klöckners „State of AI“-Talk auf der OMR (mit Cloudflare-Daten) crawlt Anthropic eine Seite rund 24.000 Mal, bevor ein einziger Besucher zurückkommt. Das Take-Away: in Zukunft geht es weniger Klicks und mehr Mentions, Citations und überprüfbare Fakten zur eigenen Marke.
JSON Schema Validation & Local Content Sandbox
Jens zeigt zwei neue Bausteine seiner Payload Content CLI, über die er in der Pilotfolge schon gesprochen hat. Beim Pull legt die CLI jetzt zusätzlich zu den Content-JSONs zwei Schemadateien ab: ein normalisiertes _schema.json (was Payload selbst über die Collection weiß) und ein _jsonschema.json im Standard-JSON-Schema-Format. Letzteres ist der eigentliche Trick — fast jede IDE versteht JSON Schema. Wer den $schema-Verweis oben in die JSON-Datei schreibt, bekommt sofort Inline-Warnungen, wenn ein Feld fehlt oder das Format nicht stimmt. Genau das Muster, das Vercel mit der vercel.json fährt.
Für AI-Agents ist das nicht nur Komfort, sondern Sicherheitsnetz: über den IDE-Diagnostics-MCP merkt ein Agent direkt, wenn er beim Editieren das Schema gebrochen hat — bevor er den Content zurück ans CMS pusht und dort gegen die Validierung läuft.
Zweites Thema, ein Experiment: die Local Content Sandbox. Anlass war ein Redesign-Projekt für eine bestehende Kundenwebsite — Astro plus Payload, viele Blöcke bleiben gleich, einige werden umgebaut. Die Frage: brauche ich für die Entwurfsphase wirklich eine zweite CMS-Instanz plus separate Datenbank? Antwort: nein. Nach einem CLI-Pull liegt der gesamte Content sowieso schon als JSON in der Codebase. Wenn ein kleiner Layer in der Astro-App den Content direkt aus diesen Dateien liest, statt die REST-API anzusprechen, denkt die Website weiter, sie spräche mit dem CMS — in Wahrheit greift sie aber lokal zu.
Der Effekt in der Live-Demo: Claude Code editiert die Hero-Section der zwischenzweistacks-Website (Namen einfügen, wieder rausnehmen), und der Browser daneben aktualisiert sich in Millisekunden — kein CMS-Roundtrip, kein Deploy. Caveats sind ehrlich genannt: virtuelle Felder und Custom Endpoints lassen sich so nicht replizieren. Aber für Drafting-Phasen, in denen man Content und Design parallel iteriert, fällt der ganze „warte vier Minuten auf den Deploy“-Overhead weg. Christoph spiegelt das aus Marketing-Sicht: gerade dort summieren sich diese kleinen Wartezeiten am Ende des Projekts auf Stunden. Die CLI ist Open Source, die Sandbox bleibt vorerst ein Experiment — vielleicht kommt dazu ein Blogpost.
Claude Code Projekt von Scratch: PRD, Architecture, Milestones
Christoph zeigt seinen wiederkehrenden Prozess, neue Projekte mit Claude Code zu starten. Schritt eins ist ausdrücklich human only: bevor irgendein Prompt rausgeht, setzt er sich hin — manchmal eine Stunde lang — und schreibt selbst auf, was er bauen will, was nicht, und welche Abgrenzungen wichtig sind. Genau diese „so soll es nicht werden“-Punkte sind später entscheidend, ähnlich wie auf einer Grounding Page.
Schritt zwei: nicht Claude Code, sondern Claude.ai im Chat öffnen. Alle unstrukturierten Gedanken in einem Prompt reinkippen und das Ziel klar benennen — drei Dokumente plus eine Skill-Empfehlung sollen am Ende stehen. Wichtig: er erzwingt ein Interview. „Überleg dir einen strukturierten Prozess, geh den Schritt für Schritt mit mir durch, jeder Schritt endet mit einer Zusammenfassung, ich bestätige, dann erst der nächste.“ Erst wenn Konsens da ist, schreibt das Modell die Dokumente.
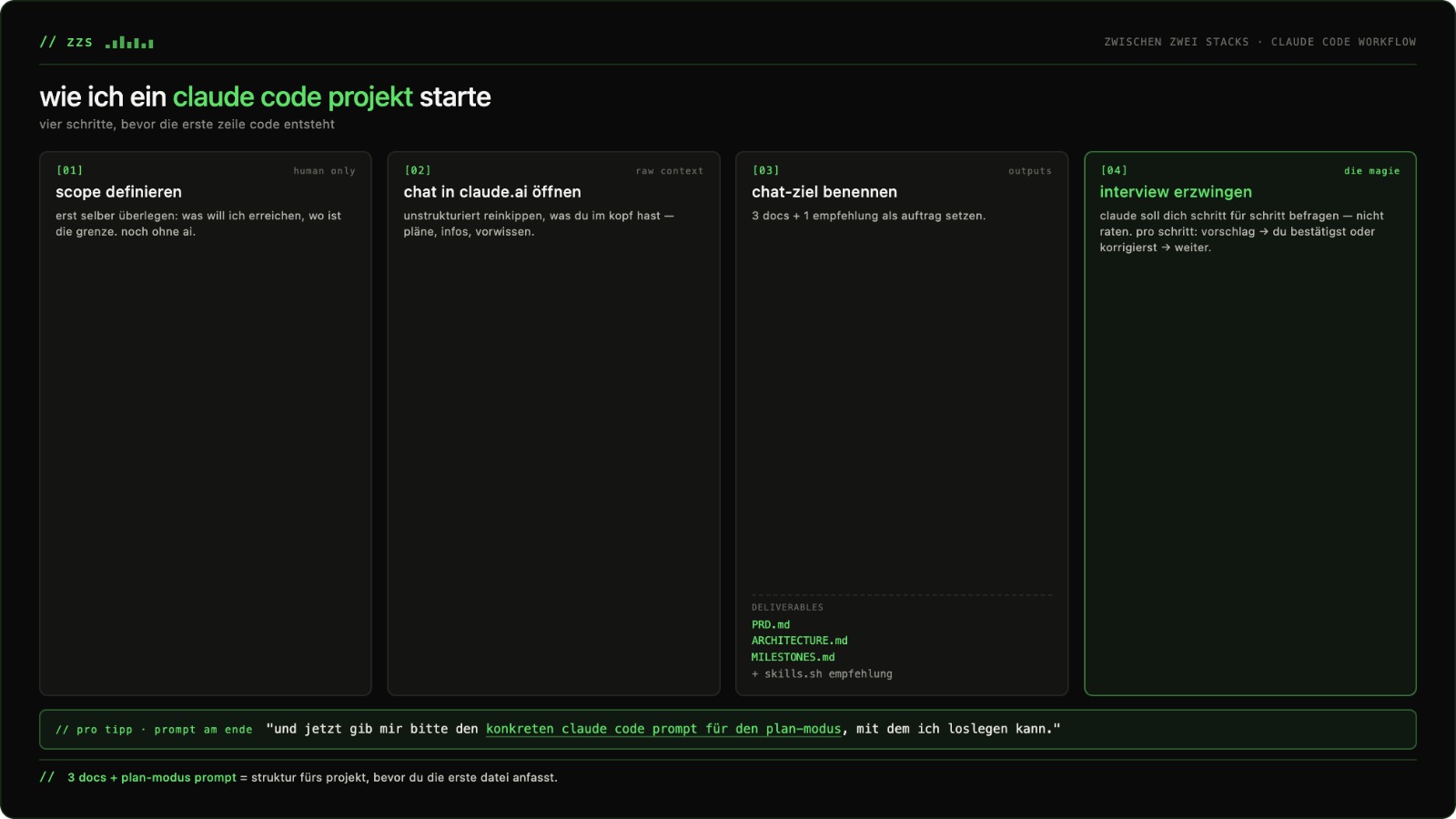
Die drei Dokumente sind immer die gleichen. PRD.md ist die Produktperspektive: Vision, Problem Statement, Zielgruppe, Ziele, Nicht-Ziele, Core Features fürs MVP. architecture.md beschreibt das technische Setup: Tech-Stack, High-Level-Struktur, Datenmodell, geplante Ordnerstruktur. milestones.md zerlegt den Weg von null bis fertig in Phasen mit klaren Test-Punkten — manuelles Testing nach jedem Milestone, erst dann geht es weiter.
Neu im Prozess: passende Skills empfehlen lassen. skills.sh sammelt prozedurales Wissen als wiederverwendbare Markdown-Anleitungen, die sich in Cloud Code oder andere Agent-Setups laden lassen. Christophs Beispiel: für ein Firebase-Projekt hat er sich „Firebase Authentication Basics“ und „Firestore Standards“ reingezogen — der Unterschied im Output war direkt spürbar. Gleichzeitig die Warnung, die zur Lage passt: Skills wie NPM-Pakete vorher prüfen. Was reingeladen wird, läuft im eigenen Kontext. Supply-Chain-Attacks sind gerade ein reales Thema, nicht nur ein Marketing-Schlagwort.
Letzter Schritt im Chat: Claude darum bitten, den konkreten ersten Claude-Code-Prompt für den Plan-Mode zu generieren. Dokumente in einen leeren Docs-Ordner schmeißen, Claude Code aufmachen, Prompt rein — los geht's. Daraus formuliert Christoph eine Haltung, die auch Jens unterschreibt: nicht ständig den nächsten Prozess oder das nächste Tool jagen, sondern einen Prozess haben und an dem iterieren. Jens ergänzt Matt Pococks viralen AI Hero-Skill „grill-me“ — drei Sätze, die den Agent dazu zwingen, den User ausgiebig zu interviewen, bevor irgendwas gebaut wird. Gleicher Reflex wie Christophs Interview-Phase. Und Christophs Kernsatz dazu: AI ist ein Tool, kein Mitarbeiter — die Zügel bleiben in der eigenen Hand.
Flue: Agent Harness Framework von Astro
Jens stellt Flue vor — ein Agent-Harness-Framework vom Astro-Team (das inzwischen zu Cloudflare gehört). Kurzer Begriffs-Check: ein Harness ist die Laufzeit- und Kontrollumgebung um ein LLM herum. Claude Code ist ein Harness. Codex ist ein Harness. Flue liefert eine Struktur, um eigene zu bauen.
Konkret ist ein Flue-Projekt ein .flue/-Ordner mit Agents, Connectors und Rollen. Jeder Agent definiert deklarativ, welches Modell genutzt wird, ob er in einer Sandbox läuft, welche Skills er referenziert, welches Input- und Output-Schema gilt und was nach dem Agent-Lauf passieren soll. Das Doku-Beispiel: ein Triage-Agent für GitHub-Issues — Modell + Sandbox + Triage-Skill, danach ein Hook, der per Git-CLI direkt einen GitHub-Kommentar mit der Zusammenfassung postet.
In der Live-Demo läuft das mitgelieferte Beispiel-Projekt lokal: ein simpler Greeter-Agent mit Rolle „warmly begrüßen plus Fun Fact“. Ein POST-Request rein, „Hello Jens“ plus Octopus-Fun-Fact zurück. Über Cloudflare-Sandboxes lässt sich der gleiche Agent in der Cloud betreiben, und über Cloudflare-Speicher-Produkte bekommt er Memory über Sessions hinweg.
Konkret im nächsten Schritt: den new-episode-Skill, der genau diese Folge hier ins CMS gedraftet hat (RSS + Transkript einlesen, Folge zusammenfassen, Cover generieren, Entwurf anlegen), als Flue-Agent verpacken. Trigger wäre dann ein Webhook von Riverside; das Ergebnis ein fertiger Entwurf im CMS — ohne dass jemand Claude Code lokal aufmachen muss. Christophs Lesart: Flue ist quasi „AI ohne Prompt verwenden“ — strukturiert, modellunabhängig, wiederverwendbar. Bericht über Praxiserfahrungen folgt in einer der nächsten Folgen.